# 大数据管理框架之 chunjun
# 简介
是一款稳定、易用、高效、批流一体的数据集成框架,目前基于实时计算引擎 Flink 实现多种异构数据源之间的数据同步与计算,已在上千家公司部署且稳定运行。
官网:https://dtstack.github.io/chunjun/
选择版本下载:https://github.com/DTStack/chunjun
# 部署
- 下载安装包
# 扩展
扩展达梦不支持实时更新操作,其实就是达梦端需要监听到修改的记录如何通过 chunjun 更新到 sink 端,达梦和 oracle 非常类似,所有这里改造 oracle 的 logminer(达梦也有)
# logminer 是什么
LogMiner 是 Oracle 公司从产品 8i 以后提供的一个实际非常有用的分析工具,使用该工具可以轻松获得 Oracle 重做日志文件(归档日志文件)中的具体内容,LogMiner 分析工具实际上是由一组 PL/SQL 包和一些动态视图组成,它作为 Oracle 数据库的一部分来发布,是 oracle 公司提供的一个完全免费的工具。
具体的说: 对用户数据或数据库字典所做的所有更改都记录在 Oracle 重做日志文件 RedoLog 中,Logminer 就是一个解析 RedoLog 的工具,通过 Logminer 解析 RedoLog 可以得到对应的 SQL 数据。
Oracle 中的 RedoLog 写入流程: Oracle 重做日志采用循环写入的方式,每一个 Oracle 实例至少拥有 2 组日志组。Oracle 重做日志一般由 Oracle 自动切换,重做日志文件在当 LGWR 进程停止写入并开始写入下一个日志组时发生切换,或在用户收到发出 ALTER SYSTEM SWITCH LOGFILE 时发生切换。如果 Oracle 数据库开启了归档功能,则在日志组发生切换的时候,上一个日志组的日志文件会被归档到归档目录里
从上面可知 Oracle 里的 RedoLog 文件分为两种:
- 当前写的日志组的文件,可通过 vlogfile 得到
- 归档的 redoLog 文件,可通过 v$archived_log 得到
v$log 文档 https://docs.oracle.com/cd/B19306_01/server.102/b14237/dynviews_1150.htm#REFRN30127
v$logfile 文档 https://docs.oracle.com/cd/B28359_01/server.111/b28320/dynviews_2031.htm#REFRN30129
v$archived_log 文档 https://docs.oracle.com/cd/E18283_01/server.112/e17110/dynviews_1016.htm
通过循环查找到最新符合要求的 RedoLog 并让 Logminer 加载分析,分析的数据在视图 vlogmnr_contents 就可以得到 Oracle 的实时数据
# Dm 配置 LogMiner
注意:
若数据量太大导致日志组频繁切换需要增加日志组数量,增大单个日志组存储大小
# 一、Dm 8 (单机版)
# 1、查询 Dm 版本信息,这里配置的是 Dm 8
-- 查看 dm 版本 | |
select * | |
from v$version; |
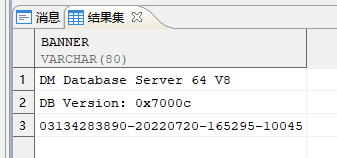
本章 DM 的版本如上图所示。
# 2、查看 Dm 是否开启日志归档
-- 查询数据库归档模式 | |
SELECT PARA_NAME, PARA_VALUE FROM V$DM_INI WHERE PARA_NAME IN ('ARCH_INI'); | |
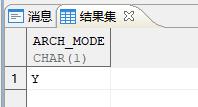
select ARCH_MODE from v$database |
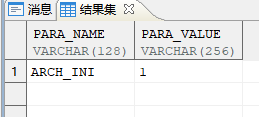
图中显示 PARA_VALUE=1 表示开启日志归档。
图中显示 `ARCH_MODE=Y 表示开启日志归档。
# 3、开启日志归档
注意:开启日志归档需要重启数据库
# a、配置归档日志保存的路径
根据自身环境配置归档日志保存路径,需要提前创建相应目录及赋予相应访问权限
# 创建归档日志保存目录 | |
mkdir -p /dm8/arch | |
# 对归档日志保存目录赋予相应权限 | |
chown -R 777 /dm8/arch | |
# 开启归档日志解析内容包含所有字段 | |
alter SYSTEM set 'RLOG_APPEND_LOGIC' = 2 both; | |
#可通过下面语句查看修改的情况 | |
select PARA_NAME, PARA_VALUE from v$dm_ini where para_name = 'RLOG_APPEND_LOGIC' |

# b、切换数据库到配置状态
alter database mount; |
# c、设置本地归档
-- 设置本地归档,归档路径,归档尺寸 | |
alter database add ARCHIVELOG 'type=local, dest=/dm8/arch, file_size=64,space_limit=10240'; |
# d、开启日志归档
-- 开启日志归档 | |
alter database ARCHIVELOG; |
# e、开启数据库
alter database open; |
# 4、配置日志组
# a、新增日志组与删除原有日志组
请与 DBA 联系,决定是否可以删除原有日志组。
-- 查看归档日志 | |
select arch_seq,path,status,arch_lsn from v$arch_file; | |
-- 增加一个新的归档日志 | |
ALTER SYSTEM ARCHIVE LOG CURRENT; |
-- 删除 10 天前的归档日志文件 | |
SELECT SF_ARCHIVELOG_DELETE_BEFORE_TIME(SYSDATE - 10); | |
-- 删除 LSN 值小于 38858 之前的归档日志文件 | |
SELECT SF_ARCHIVELOG_DELETE_BEFORE_LSN(38858); |
# 5、检查是否安装 LogMiner 工具
使用包内的过程和函数之前,如果还未创建过系统包,请先调用系统过程创建系统包:
SP_CREATE_SYSTEM_PACKAGES (1,'DBMS_LOGMNR'); |
# 6、尝试使用 LogMiner 工具分析日志文件
# a、查看可以分析的归档日志
-- 查看所有归档日志 | |
SELECT NAME , FIRST_TIME , NEXT_TIME , FIRST_CHANGE# , NEXT_CHANGE# FROM V$ARCHIVED_LOG; |
# b、添加一条归档日志
-- 添加要分析的文件名 | |
DBMS_LOGMNR.ADD_LOGFILE('/dmdata/dmarch/ARCHIVE_LOCAL1_0x2921FFFA[0]_2023-04-10_16-43-20.log') | |
-- 可以查看已经添加分析的归档日志 | |
SELECT LOW_SCN, NEXT_SCN, LOW_TIME, HIGH_TIME, LOG_ID, FILENAME FROM V$LOGMNR_LOGS |
# c、启动归档日志文件分析
-- 开始分析 | |
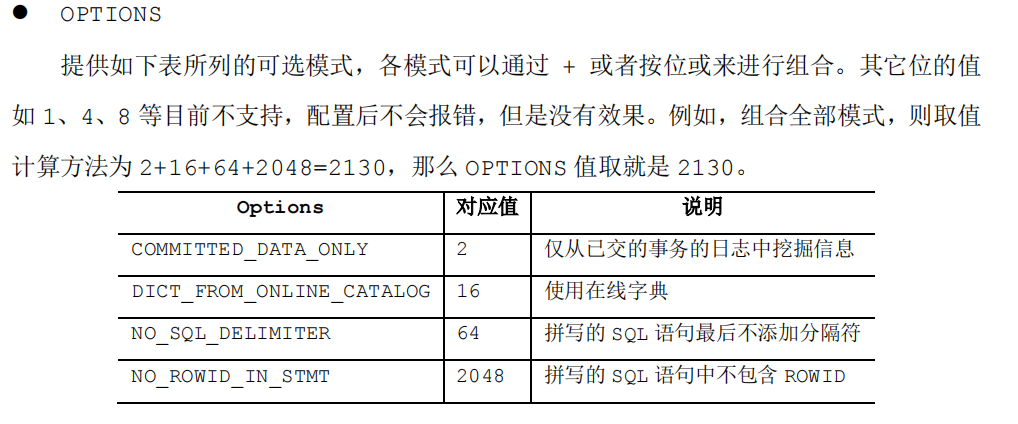
dbms_logmnr.start_logmnr(Options=>2128); | |
-- 关于 Options 参数说明看下图 |
d、查看分析结果
-- 查看分析结果 | |
SELECT * FROM V$LOGMNR_CONTENTS |
e、关闭分析结果
-- 关闭分析结果 | |
DBMS_LOGMNR.END_LOGMNR(); |
注意:在重新分析一个新的归档日志前需要关闭分析结果才能开始
至此,Dm 数据库 LogMiner 实时采集配置完毕。
# 达梦 LogMiner Source
# 介绍
DmLogMiner 插件支持配置监听表名称以及读取起点读取日志数据。DmLogMiner 在 checkpoint 时保存当前消费的位点,因此支持续跑。
其实就是持续读取达梦归档日志的内容并解析归档日志就能得到是什么类型的操作,读取成功并且写入到 sink 端后,将 lsn 后移
# 支持版本
dm7,dm8
# 插件名称
| Sync | DmLogMinerreader、DmLogMinersource |
|---|---|
| SQL | DmLogMiner-x |
# 参数说明
# 1、Sync
jdbcUrl
- 描述:Dm 数据库的 JDBC URL 链接
- 必选:是
- 参数类型:string
- 默认值:无
username
- 描述:用户名
- 必选:是
- 参数类型:string
- 默认值:无
password
- 描述:密码
- 必选:是
- 参数类型:string
- 默认值:无
table
- 描述: 需要监听的表,格式为:schema.table,schema 不能配置为 *,但 table 可以配置监听指定库下所有的表,如:["schema1.table1","schema1.table2","schema2."]
- 必选:否,不配置则监听除
SYS库以外的所有库的所有表变更信息 - 字段类型:数组
- 默认值:无
splitUpdate
- 描述:当数据更新类型为 update 时,是否将 update 拆分为两条数据,具体见【七、数据结构说明】
- 必选:否
- 字段类型:boolean
- 默认值:false
cat
- 描述:需要监听的操作数据操作类型,有 UPDATE,INSERT,DELETE 三种可选,大小写不敏感,多个以,分割
- 必选:否
- 字段类型:String
- 默认值:UPDATE,INSERT,DELETE
readPosition
- 描述:Dm 实时采集的采集起点
- 可选值:
- all: 从 Dm 数据库中最早的归档日志组开始采集 (不建议使用)
- current:从任务运行时开始采集
- time: 从指定时间点开始采集
- scn: 从指定 SCN 号处开始采集
- 必选:否
- 字段类型:String
- 默认值:current
startTime
- 描述: 指定采集起点的毫秒级时间戳
- 必选:当
readPosition为time时,该参数必填 - 字段类型:Long (毫秒级时间戳)
- 默认值:无
startSCN
- 描述: 指定采集起点的 SCN 号
- 必选:当
readPosition为scn时,该参数必填 - 字段类型:String
- 默认值:无
fetchSize
- 描述: 批量从 v$logmnr_contents 视图中拉取的数据条数,对于大数据量的数据变更,调大该值可一定程度上增加任务的读取速度
- 必选:否
- 字段类型:Integer
- 默认值:1000
queryTimeout
- 描述: LogMiner 执行查询 SQL 的超时参数,单位秒
- 必选:否
- 字段类型:Long
- 默认值:300
supportAutoAddLog
- 描述:启动 LogMiner 是否自动添加日志组 (不建议使用)
- 必选:否
- 字段类型:Boolean
- 默认值:false
pavingData
- 描述:是否将解析出的 json 数据拍平,具体见【七、数据结构说明】
- 必选:否
- 字段类型:boolean
- 默认值:false
# 2、SQL
url
- 描述:Dm 数据库的 JDBC URL 链接
- 必选:是
- 参数类型:string
- 默认值:无
username
- 描述:用户名
- 必选:是
- 参数类型:string
- 默认值:无
password
- 描述:密码
- 必选:是
- 参数类型:string
- 默认值:无
table
- 描述:需要解析的数据表。
- 注意:SQL 任务只支持监听单张表,且数据格式为 schema.table
- 必选:否
- 字段类型:string
- 默认值:无
cat
- 描述:需要监听的操作数据操作类型,有 UPDATE,INSERT,DELETE 三种可选,大小写不敏感,多个以,分割
- 必选:否
- 字段类型:String
- 默认值:UPDATE,INSERT,DELETE
read-position
- 描述:Dm 实时采集的采集起点
- 可选值:
- all: 从 Dm 数据库中最早的归档日志组开始采集 (不建议使用)
- current:从任务运行时开始采集
- time: 从指定时间点开始采集
- scn: 从指定 SCN 号处开始采集
- 必选:否
- 字段类型:String
- 默认值:current
start-time
- 描述: 指定采集起点的毫秒级时间戳
- 必选:当
readPosition为time时,该参数必填 - 字段类型:Long (毫秒级时间戳)
- 默认值:无
start-scn
- 描述: 指定采集起点的 SCN 号
- 必选:当
readPosition为scn时,该参数必填 - 字段类型:String
- 默认值:无
fetch-size
- 描述: 批量从 v$logmnr_contents 视图中拉取的数据条数,对于大数据量的数据变更,调大该值可一定程度上增加任务的读取速度
- 必选:否
- 字段类型:Integer
- 默认值:1000
query-timeout
- 描述: LogMiner 执行查询 SQL 的超时参数,单位秒
- 必选:否
- 字段类型:Long
- 默认值:300
support-auto-add-log
- 描述:启动 LogMiner 是否自动添加日志组 (不建议使用)
- 必选:否
- 字段类型:Boolean
- 默认值:false
io-threads
- 描述:IO 处理线程数,最大线程数为 3
- 必选:否
- 字段类型:int
- 默认值:1
max-log-file-size
- 描述:logminer 一次性加载的日志文件的大小,默认 5g,单位 byte
- 必选:否
- 字段类型:long
- 默认值:510241024*1024
transaction-cache-num-size
- 描述:logminer 可缓存 DML 的数量
- 必选:否
- 字段类型:long
- 默认值:800
transaction-expire-time
- 描述:logminer 可缓存的失效时间,单位分钟
- 必选:否
- 字段类型:int
- 默认值:20
start-mode
- 描述:执行的模式,当为
full则等待全量执行完毕才会执行增量, 当为increment则直接执行增量 - 必选:否
- 字段类型:string
- 默认值:full
- 描述:执行的模式,当为
case-sensitive
- 描述:配置的 flinksql 的 ddl 结构表是否和数据的表字段区分大小写
- 必选:否
- 字段类型:Boolean
- 默认值:false
file-cache-path
- 描述:当内存中存储的数据超过阈值,内存数据转存到文件的文件路径
- 必选:否
- 字段类型:String
- 默认值:System.getProperty ("user.dir") + "/dm_file_cache"
file-cache-critical-value
- 描述:内存存储归档日志数据的记录数大小的阈值,超过阈值则会转存到
file-cache-path,根据机器性能调整 - 必选:否
- 字段类型:Long
- 默认值:2000
- 描述:内存存储归档日志数据的记录数大小的阈值,超过阈值则会转存到
# 数据结构
在 2021-06-29 23:42:19 (时间戳:1624981339000) 执行:
INSERT INTO TIEZHU.RESULT1 ("id", "name", "age") | |
VALUES (1, 'a', 12) |
在 2021-06-29 23:42:29 (时间戳:1624981349000) 执行:
UPDATE TIEZHU.RESULT1 t | |
SET t."id" = 2, | |
t."age" = 112 | |
WHERE t."id" = 1 |
在 2021-06-29 23:42:34 (时间戳:1624981354000) 执行:
DELETE | |
FROM TIEZHU.RESULT1 | |
WHERE "id" = 2 |
1、pavingData = true, splitUpdate = false RowData 中的数据依次为:
//scn schema, table, ts, opTime, type, before_id, before_name, before_age, after_id, after_name, after_age
[49982945,"TIEZHU", "RESULT1", 6815665753853923328, "2021-06-29 23:42:19.0", "INSERT", null, null, null, 1, "a", 12]
[49982969,"TIEZHU", "RESULT1", 6815665796098953216, "2021-06-29 23:42:29.0", "UPDATE", 1, "a", 12 , 2, "a", 112]
[49982973,"TIEZHU", "RESULT1", 6815665796140896256, "2021-06-29 23:42:34.0", "DELETE", 2, "a",112 , null, null, null]
2、pavingData = false, splitUpdate = false RowData 中的数据依次为:
//scn, schema, table, ts, opTime, type, before, after
[49982945, "TIEZHU", "RESULT1", 6815665753853923328, "2021-06-29 23:42:19.0", "INSERT", null, {"id":1, "name":"a", "age":12}]
[49982969, "TIEZHU", "RESULT1", 6815665796098953216, "2021-06-29 23:42:29.0", "UPDATE", {"id":1, "name":"a", "age":12}, {"id":2, "name":"a", "age":112}]
[49982973, "TIEZHU", "RESULT1", 6815665796140896256, "2021-06-29 23:42:34.0", "DELETE", {"id":2, "name":"a", "age":112}, null]
3、pavingData = true, splitUpdate = true RowData 中的数据依次为:
//scn, schema, table, ts, opTime, type, before_id, before_name, before_age, after_id, after_name, after_age
[49982945,"TIEZHU", "RESULT1", 6815665753853923328, "2021-06-29 23:42:19.0", "INSERT", null, null, null, 1, "a",12 ]
//scn, schema, table, opTime, ts, type, before_id, before_name, before_age
[49982969, "TIEZHU", "RESULT1", 6815665796098953216, "2021-06-29 23:42:29.0", "UPDATE_BEFORE", 1, "a", 12]
//scn, schema, table, opTime, ts, type, after_id, after_name, after_age
[49982969, "TIEZHU", "RESULT1", 6815665796098953216, "2021-06-29 23:42:29.0", "UPDATE_AFTER", 2, "a", 112]
//scn, schema, table, ts, opTime, type, before_id, before_name, before_age, after_id, after_name, after_age
[49982973, "TIEZHU", "RESULT1", 6815665796140896256, "2021-06-29 23:42:34.0", "DELETE", 2, "a", 112, null, null, null]
4、pavingData = false, splitUpdate = true RowData 中的数据依次为:
//scn, schema, table, ts, opTime, type, before, after
[49982945, "TIEZHU", "RESULT1", 6815665753853923328, "2021-06-29 23:42:19.0", "INSERT", null, {"id":1, "name":"a", "age":12}]
//scn, schema, table, ts, opTime, type, before
[49982969, "TIEZHU", "RESULT1", 6815665796098953216, "2021-06-29 23:42:29.0", "UPDATE_BEFORE", {"id":1, "name":"a", "age":12}]
//scn, schema, table, ts, opTime, type, after
[49982969, "TIEZHU", "RESULT1", 6815665796098953216, "2021-06-29 23:42:29.0", "UPDATE_AFTER", {"id":2, "name":"a", "age":112}]
//scn, schema, table, ts, opTime, type, before, after
[49982973, "TIEZHU", "RESULT1", 6815665796140896256, "2021-06-29 23:42:34.0", "DELETE", {"id":2, "name":"a", "age":112}, null]
- scn:Dm 数据库变更记录对应的 scn 号
- type:变更类型,INSERT,UPDATE、DELETE
- opTime:数据库中 SQL 的执行时间
- ts:自增 ID,不重复,可用于排序,解码后为 ChunJun 的事件时间,解码规则如下:
long id=Long.parseLong("6815665753853923328"); | |
long res=id>>22; | |
DateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); | |
System.out.println(sdf.format(res)); //2021-06-29 23:42:24 |
# 数据类型
| 是否支持 | 数据类型 |
|---|---|
| 支持 | DATE,TIMESTAMP,TIMESTAMP WITH LOCAL TIME ZONE,TIMESTAMP WITH TIME ZONE, CHAR,NCHAR,NVARCHAR2,ROWID,VARCHAR2,VARCHAR,LONG,RAW,LONG RAW,INTERVAL YEAR,INTERVAL DAY,BLOB,CLOB,NCLOB, NUMBER,SMALLINT,INT INTEGER,FLOAT,DECIMAL,NUMERIC,BINARY_FLOAT,BINARY_DOUBLE |
| 不支持 | BFILE,XMLTYPE,Collections |
# 脚本示例
见项目内 ChunJun : Local : Test 模块中的 demo 文件夹。